著者 svl , 06月2024 . に発表されました 鉄
2024 年、NVIDIA は期待の「Blackwell」シリーズからフラッグシップの GeForce RTX 5090 モデルのみをリリースすることに重点を置きます。この動きにより、同社は生産リソースをより慎重に管理し、特に GPU セグメントでの激しい競争を考慮して市場の需要に対応できるようになります。限定リリースは、以前の RTX 40 シリーズの残り在庫を売却する必要があるためでもあり、これは同社の戦略に大きな影響を与えます。
GeForce RTX 5090 は、前世代からの大幅な進歩を約束し、最先端の機能とパフォーマンスを提供します。 RTX 5090 の発売の一環として「Blackwell」アーキテクチャが発表されると、シリーズの後続のモデルに適用される可能性のある主要な機能と革新性が明らかになります。この戦略により、NVIDIA は市場で主導的な地位を維持できるだけでなく、同じく Blackwell アーキテクチャをベースとした利益率の高い AI GPU に焦点を当てて製品ラインを最適化することもできます。
ソース GameGPU.tech
著者 svl , 06月2024 . に発表されました 鉄
ntel は、第 13 世代および第 14 世代プロセッサの安定性の問題に対処するために、マザーボード メーカーに対し、メイン BIOS プロファイルとして「インテル標準設定」を採用するよう要求しました。この決定は、以前に推奨されたプロファイルを使用したときにシステムの不安定性、クラッシュ、ブルー スクリーン (BSOD) インシデントが発生するという多数の報告を受けて行われました。」Extremeこれにより、プロセッサが推奨電力制限を超えて動作し、動作の不整合が生じることがよくあります。
Intel の決定は、すぐに使えるこれらのプロセッサーの構成を標準化することでシステムの安定性を確保する方向への移行を浮き彫りにしています。推奨される「インテル標準設定」は、プロセッサーをより安全な動作パラメーター内に維持するように設計されており、最大のパフォーマンスよりも信頼性を重視しています。この変更により、ユーザーから報告されるハードウェア障害とシステムの不安定性の数が大幅に減少すると予想されます。
この調整には、プロセッサへの過度の負荷を防ぐレベルに電力レベル (PL) と最大電流 (IccMax) を設定することが含まれます。具体的には、インテルは、PL1/PL2 設定を、「Extreme」、最大 253 W に達する可能性があります。この電力上限の削減は、プロセッサーの熱要件と電力要件を制限し、インテルの技術仕様および熱設計ポイントとより密接に一致させることを目的としています。
マザーボードのメーカーは、31 年 2024 月 XNUMX 日までにこれらの変更をデフォルトの BIOS 設定に実装する必要があります。インテルは、これによりシステムのクラッシュや不安定性といった当面の問題が解決されるだけでなく、プロセッサーやマザーボード自体の寿命が延び、動作中の熱的および電気的ストレスが軽減されると考えています。
この取り組みは、インテルのプロセッサーがすべての標準的なコンピューティング環境で確実に動作することを保証することで、自社製品に対する顧客の満足度と信頼を高めるというインテルの広範な戦略の一環です。インテルはまた、パートナーと協力してこれらの設定の実装を監視し、システムのパフォーマンスと安定性への影響を評価する予定です。ユーザーおよび技術コミュニティからのフィードバックに基づいて、追加の調整と最適化が検討される場合があります。
ソース GameGPU.tech
著者 svl , 06月2024 . に発表されました 鉄
最近の米国政府のオークションでは、シャイアン スーパーコンピューターが 480,085 ドルで落札されました。このシステムには、8,064 GHz の 5 コアと 2697 スレッドを備えた 4 個の Intel Xeon E18-36 v2,3 プロセッサと 313 TB の RAM が搭載されており、ECC 準拠の各 4,890 GB の 64 モジュールに分割されています。このスーパーコンピューターは、ワイオミング州や国内の他の地域の科学機関で、気候と気象の研究のために XNUMX 年間使用されました。
購入者にとって残念なことに、このマシンには 32 ペタバイトの高速ストレージが付属していませんでした。ただし、コンポーネントの品質が高いため、eBay の販売者はプロセッサと RAM を約 700,000 万ドルで再販し、大きな利益を得ることができます。
部品の故障率の高さと、水漏れを引き起こすクイックリリースカップリングの欠陥などのメンテナンスの困難さが売上の原動力となった。メンテナンスの困難により交換が必要となり、シャイアンは HP の 35 万ドルから 40 万ドルの新しいスーパーコンピューター Derecho に置き換えられる予定です。
購入者は、30 台のサーバー ラックを施設から移動するための輸送を自分で手配する必要があります。政府は輸送を提供しません。また、マシンを稼働させるために必要なイーサネットや光ケーブルも提供しません。したがって、この売却額はシャイアンの当初の建設費 (推定 2 万ドル) の 25% にすぎませんでした。
ソース GameGPU.tech
著者 svl , 05月2024 . に発表されました 鉄
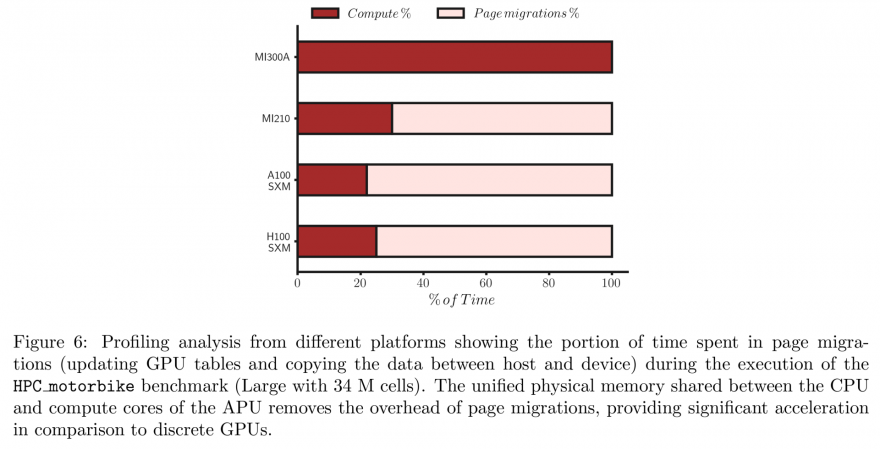
AMD は、最新のハイパフォーマンス コンピューティング (HPC) APU、Instinct MI300A APU を発表しました。これは、従来のディスクリート GPU に比べて大幅なパフォーマンスの向上を実現します。この製品は、共有 HBM メモリ プールにアクセスできるように、高性能 CPU と GPU を XNUMX つのパッケージに組み合わせた「Exascale APU」コンセプトを実装しています。
Instinct MI300A APU は、ワットあたりの高いパフォーマンスが必要なタスク向けに設計されており、大量のデータを処理する必要がある科学および工学アプリケーションに最適です。これらの APU では、数百万行のコードの移植、構成、保守にも多大な労力が必要であり、これは困難な場合がありますが、OpenMP や OpenACC などの一般的なソフトウェア モデルを使用すると、プロセスが容易になります。
「ユニファイド メモリと OpenMP を使用した AMD Instinct MI300A への HPC アプリケーションの移植」と題された研究論文では、オープン C++ ライブラリである OpenFOAM フレームワークを使用して、OpenMP を使用して MI300A にコードを移植する柔軟性とアクセシビリティを実証しました。
OpenFOAM オートバイ HPC ベンチマークを使用したパフォーマンス評価では、AMD Instinct MI300A APU が AMD Instinct MI210、NVIDIA A100 および H100 (80GB) と比較されました。結果は、Instinct MI300A は NVIDIA H100 と比較して 210 倍、Instinct MIXNUMX と比較して XNUMX 倍のパフォーマンス向上を実現することを示しました。
MI300A の主な利点は、CPU コアと GPU 計算ユニット間で共有される単一の物理メモリの使用です。これにより、メモリ ページを移行する必要がなくなり、動作速度が大幅に向上します。このアーキテクチャによりパフォーマンスが大幅に向上し、AMD Instinct MI300A は次世代コンピューティングにとって優れた選択肢となります。
ソース GameGPU.tech
著者 svl , 05月2024 . に発表されました 鉄
Intel は、Arrow Lake-S プロセッサの新しいシリーズをリリースする準備をしています。これは、以前の Raptor Lake-S シリーズとは周波数が著しく異なります。 Weibo ユーザー MebiuW からの最新のリークによると、主力 Core Ultra 9 285K は最大 5.5 GHz の周波数で動作しますが、これは現在の主力 Core i700-9KS の周波数 14900 GHz よりも 6.2 MHz 低いです。
新しい Arrow Lake-S プロセッサは、8 個の P コア Lion Cove コアと 16 個の E コア Skymont コアを含む 8+16 コア構成を使用します。最大周波数の低下にもかかわらず、アーキテクチャの改善により、同様の消費電力で第 10 世代プロセッサと比較して最大 14% のパフォーマンス向上が達成されることが期待されています。
IntelはComputex 2024で新シリーズを発表する予定で、そこで高速DDR5-6400メモリのサポートもデモする予定だ。新しいプロセッサの価格は、AI 機能の追加と統合された Xe-LPG グラフィックスにより、以前のモデルよりわずかに高くなることが予想されます。
ソース GameGPU.tech
著者 svl , 02月2024 . に発表されました 鉄
AMD 製品に関する正確な予測で知られるインサイダー Kepler_L2 からの最新のリークによると、同社は新しい RDNA4 GPU アーキテクチャに、特にレイ トレーシングのハードウェア アクセラレーションの点で大幅な変更を加えました。 RDNA3 アーキテクチャのみを改良した以前のバージョンの RDNA2 とは異なり、RDNA4 ではレイ トレーシング用のまったく新しいブロックが導入されます。
しかし、予想されるパフォーマンスの向上にも関わらず、AMD は大型の Navi4 チップを製造する計画をキャンセルしました。これは、RDNA4 RT に関連するイノベーションはミッドエンドおよびハイエンドのモデルでのみ利用できることを意味し、愛好家は次世代の RDNA5 を待つ必要があります。
噂によると、PlayStation 5 Pro は RDNA4 に基づく RT ハードウェア アクセラレーションを使用する予定です。具体的には、PS5 Pro は 8 レベルのボリューム階層 (BVH8) を横断するシェーダーを処理できることが期待されていますが、現在の RT ソリューションは 4 レベルの階層に限定されています。これにより、理論的には各データ サイクルのスループットが XNUMX 倍になる可能性があります。
ソース GameGPU.tech
著者 svl , 02月2024 . に発表されました 鉄
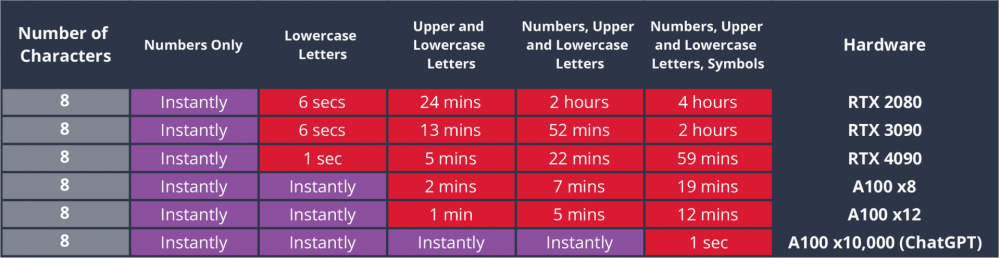
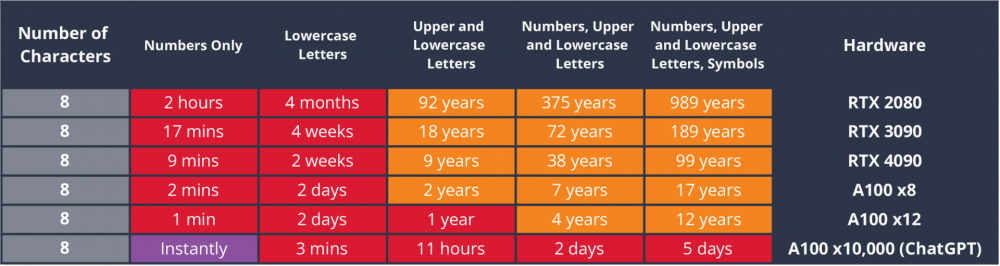
Hive Systems は、フラッグシップ モデルの GeForce RTX 4090 を含む、NVIDIA ビデオ カードのパスワード ハッシュ アルゴリズムの比較テストを実施しました。この調査では、古い MD5 と最新の bcrypt を使用した場合に保護レベルがどのように異なるかを示しました。
テスト結果によると、GeForce RTX 4090 は、MD5 アルゴリズムを使用して暗号化されたパスワードをわずか 99 時間で解読できましたが、より安全な bcrypt アルゴリズムを使用してパスワードを復号するには約 XNUMX 年かかります。これは、データ セキュリティにおける bcrypt の重要な利点を強調しています。
また、10,000 台の NVIDIA のモデル A100 が MD5 で保護されたパスワードを XNUMX 秒以内に復号できることも判明し、この方法のセキュリティが最新の復号ツールに対して不十分であることが実証されました。セキュリティ強化の文脈において、企業はデータの安全性を確保するためにハッシュを含む多層セキュリティを使用しています。
ソース GameGPU.tech
著者 svl , 01月2024 . に発表されました 鉄
NVIDIA は、現在の NPU を大幅に上回るパフォーマンスを約束する新しいプレミアム AI PC エコシステムの導入により、人工知能分野での優位性を維持し続けています。 AI 対応アプリケーションの数が増加し (500 以上)、100 億人を超える RTX ユーザーのインストール ベースを持つ同社は、市場での地位をさらに強化することを目指しています。
NVIDIA は、AI パフォーマンスを大幅に向上させる Chat With RTX や TensorRT など、RTX GPU に最適化された幅広いツールを提供しています。同社は DLSS 3.5 および DLSS 3.7 テクノロジーの開発にも積極的に取り組んでいます。これらのテクノロジーにより、ゲームのグラフィックスが向上するだけでなく、モディファイアが RTX Remix プラットフォームを通じて古いゲームを更新できるようになります。
RTX ベースのシステムは、NPU の能力をはるかに上回る数百 TOPS のパフォーマンスを誇ります。このようなパフォーマンスにより、RTX GPU は AI タスクに高いパフォーマンスを必要とするユーザーにとって好ましい選択肢となります。 NVIDIA は、GPU が一般的なコンピューティング機能だけでなく、AI と連携するための特殊なテンソル コアも提供すると強調しています。
今年、PC メーカーは NPU 能力を 45 ~ 50 TOPS まで大幅に向上させると予想されていますが、これらの数値でさえ RTX GPU のパフォーマンスに匹敵することはできません。これにより、NVIDIA は AI PC 市場をさらに発展させる上で有利な立場にあり、より高いパフォーマンスだけでなく、AI を日常業務に統合するのに役立つ幅広いアプリケーションをユーザーに提供します。
ソース GameGPU.tech
著者 svl , 4月30 2024 . に発表されました 鉄
新しい Apple ガジェットが毎年リリースされるのは、良い伝統となっています。したがって、2024年には、新しいiPhone 16とそのさまざまな改良版、Plus、Pro、Pro Maxがリリースされるでしょう。アメリカのメーカーは、スマートフォンの見た目の変化と機能の拡張の両方を約束しています。したがって新しい iphone これはApple製品のファンが待ち望んでいたものです。
スマートフォンの大きな変化
主力ガジェットの新しいモデルでは、メーカーはリフレッシュ レートが向上した、より高度な OLED ディスプレイを使用する予定です。このおかげで、デバイス上の画像はより鮮明で滑らかになります。ゲーム愛好家は特にこれに気づくでしょう - 新しいガジェットのダイナミックな画像はフリーズしません。そうすることで、何が起こっているのかをリアルに感じることができます。新しい画面は、ビデオやその他のコンテンツの視聴にもさらに便利です。ディスプレイが直射日光にさらされても、すべての画像を表示できます。
その他の改善点は次のとおりです。
先進のカメラシステム。新しい iPhone には、集光性を高めるためのセンサーが搭載されています。これにより、暗い場所でも鮮明な写真を撮ることができます。高度な人工知能機能の導入により、全体的な画質の向上も期待されます。これで、プロのカメラで撮影したかのように見えるようになります。
新しいオペレーティング システム。このガジェットは更新された iOS 上で動作することが予想されます。インターフェイスがわずかに変更され、セキュリティ設定が拡張されます。最も重要なことは、要求の厳しいプログラムを実行しても問題ないということです。複数のアプリケーションを同時に開いて、中断のないデバイスの操作を楽しむことができます。
仕事の自主性が高まります。新しいチップセットを使用すると、ガジェットのパフォーマンスが向上します。アプリケーションの動作を最適化すると、エネルギーの消費が少なくなります。自律性の向上とは、継続的な充電に依存せず、時間制限なく必要なすべてのタスクを実行できる能力です。
Apple エコシステム内の他の製品との統合が向上しました。このアメリカのブランドのカタログには、ラップトップから時計まで、多くのガジェットが含まれています。改善された同期のおかげで、健康状態を監視し、ファイルをより速く共有し、単一の通知を見逃すことがなくなりました。
これらの改善により、新しい iPhone を購入するのが賢明になります。さらに、そのようなガジェットは長期間関連し続けます。
新しい iPhone は長期的な投資です
iPhone 16は、単なる前モデルの改良版ではありません。ディスプレイからカメラ、パフォーマンスから他のデバイスとの統合に至るまで、あらゆる面での改善が期待されています。
これにより、スマートフォンでの基本的なタスクの実行がさらに快適でアクセスしやすくなり、スマートフォン自体の安全性と機能性が向上します。これはユーザーエクスペリエンスにプラスの影響を与えます。そして、ガジェットの強力な特性により、多くのタスクを長期間処理することができます。
著者 svl , 4月28 2024 . に発表されました 鉄
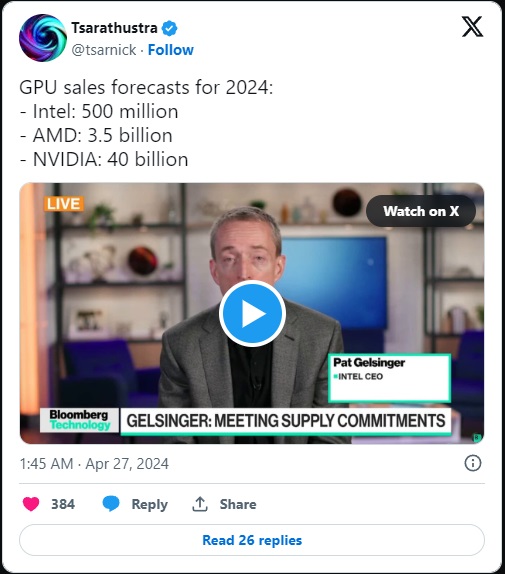
NVIDIA は人工知能市場での地位を強化し続けており、40 年の AI アクセラレータの売上高は約 2024 億ドルになると予測しています。これは、Intel のほぼ 80 倍、AMD の 11.4 倍に相当し、業界における同社の主導的地位を裏付けています。
ブルームバーグ テクノロジーによると、AMD やインテルなどの NVIDIA の競合企業は、AI デバイスの販売による収益がそれぞれ 3.5 億ドルと 500 億ドルと大幅に減少すると予想しています。これは、NVIDIA が AI アクセラレータ市場で競合他社とのリードを維持しているだけでなく、さらにリードを拡大していることを示しています。
NVIDIA は、AI における最新の進歩である Blackwell GPU も披露しました。Blackwell GPU の価格は 30 ユニットあたり 40 ドルから XNUMX ドルで、世界で最も強力なものの XNUMX つとなります。この開発は、競争の激しい業界で優れた技術を維持するための同社の戦略の一環です。
ソース GameGPU.tech